写在前面
《STP(802.1d)简述》中描述了STP协议实现loop-free的原理,举例说明了根桥及端口的选举规则,当发生链路故障时的收敛过程,最后列举了加快STP收敛的特性及安全特性。STP的最大收敛时间可达50秒左右,为了加快收敛时间,RSTP(rapid STP)诞生了。RSTP主要通过P/A机制减少端口状态切换时间,通过处理inferior BPDU减少BPDU老化时间,并且集成了portfast、uplinkfast、backbonefast机制。下面主要阐述两者之间的差异,以及RSTP实现快速收敛的一些细节。
RSTP与STP的差异
RSTP中根桥的选举规则,端口的选举规则和STP保持一致。superior BPDU依然是其中的核心。差异主要体现在下面几点。
端口状态
STP中的disabled、blocking、listening三种状态合并到RSTP的discarding。STP中的端口状态过于细分,比如blocking只能接收BPDU,而listening可以接收和发送BPDU,两者都不能学习MAC地址。过多的状态切块增加了收敛时间。当然,多的状态可以极大的减少网络环路的风险。两者端口状态对比如下:
| STP | RSTP | 是否在活动的拓扑中 | 是否学习mac地址 |
|---|---|---|---|
| disabled | discarding | no | no |
| blocking | discarding | no | no |
| listening | discarding | no | no |
| learning | learning | yes | yes |
| forwarding | forwarding | yes | yes |
究其原因,RSTP中通过P/A机制主动协商可以直接将端口从discarding状态转换到forwarding,而不是STP中通过定时器机制经过forward_delay后再切换状态。
端口角色
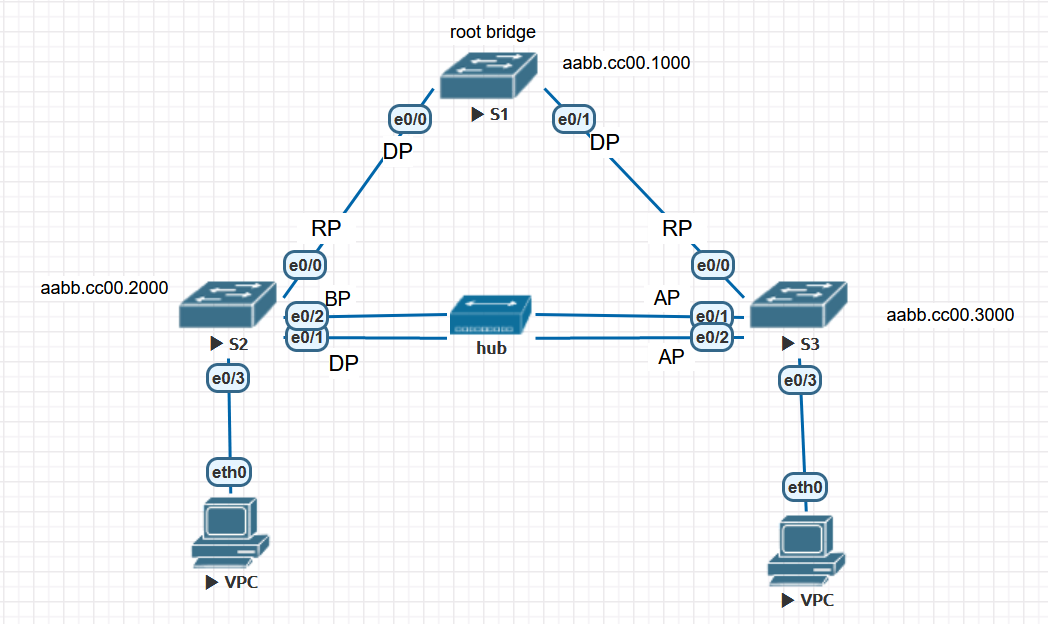
RSTP中增加了一种端口角色backup port. 如上图所示,S2的eth2端口为BP。非根交换机收到自己发出的BPDU时,对比端口上发出和收到的BPDU,如果发出的是superior BPDU,那么成为DP,否则成为BP。注意与AP端口的差异:
- AP是端口收到从
其它交换机发来的superior BPDU,是RP的备份,这是uplinkfast实现的原理 - BP是端口收到从
自身交换机发来的superior BPDU, 是DP的备份,uplinkfast对BP不生效,BP在现实网络中很少见,基本用不到。图中通过在S2和S3中加一个hub来实现,如果没有hub,S2的eth1和eth2都是DP。
BPDU的变化
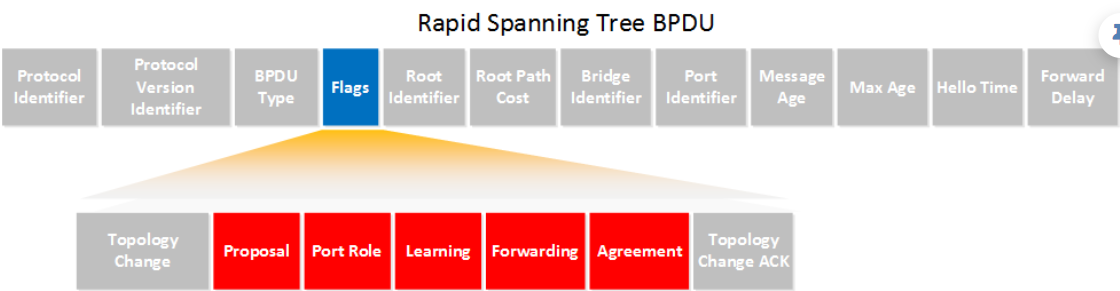
RSTP的BPDU与STP的主要在三个字段上有差异:
- protocol version identifier:stp为0,rstp为2. rstp向下兼容stp
- BPDU type: stp为0, rstp为2。rstp中没有类型为0x80的TCN报文,在配置BPDU中使用TC flag替代
- flags:stp中只使用TC和TCA两个flags,rstp中使用上了剩下的6 bits, 其中bit3和bit2表示端口角色:
- 0x00 表示未知类型
- 0x01 表示RP
- 0x10 表示AP或BP
- 0x11 表示DP
BPDU的发送
STP中根桥周期(hello time)发送BPDU,非根桥从RP收到然后从DP中继出去。RSTP非根桥自己生成BPDU(根据缓存的根桥cache),周期(hello time)通过DP向外发送
BPDU的超时
STP上如果端口有存储的BPDU,max_age时间内没有收到superior BPDU后便会对其超时。RSTP通过BPDU实现类似ospf中的keepalive机制,如果连续三个hello_time时间内没有从邻居收到BPDU,那么就认为该链路故障,并且立即清除所有MAC地址。
边缘端口
STP的收敛优化里面有portfast的概念,在rstp中则称之为edge port, 即连接主机的端口。开启edge port的端口不需要经历discarding、learning的过度,而是直接变成forwarding,端口up、down也不会产生TC。注意边缘端口的链路类型只能是p2p, 即全双工链路,区别于半双工链路(shared类型)。
需要注意的是RSTP中同样需要管理员手动指定edge port。uplinkfast和backbonefast特性则是自动运行的。
PA协商机制(重要区别)
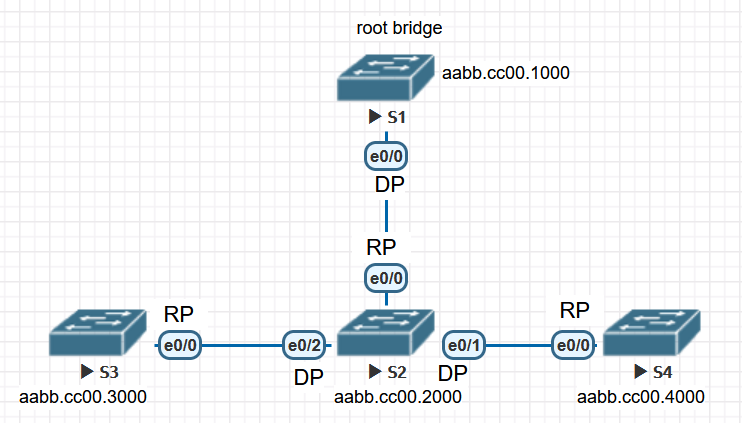
PA机制的基本原理就是:将下游block之后,再将上游forwarding,这种过程向下传导,直至整个RSTP开始运转,下游block的时候依然可以传输BPDU,进行角色选举。需要把STP的选举机制联想起来,不要孤立的看待PA机制。
通过上图来介绍P/A协商机制的原理。
- 当设备上电后,S1、S2均认为自己是根桥并向外发送BPDU(proposal flag置位),端口状态均为blocking
- S2的eth0收到S1的eth0发来的superior BPDU,确定S1是根桥,S2的eth0成为RP(立即切换成forwarding),将所有非边缘DP(eth1,eth2)状态置为block, 并通过非边缘DP发送BPDU(根桥是S1,proposal flag置位),之后向根桥发送BPDU(TC置位, agreement置位,该BPDU是proposal BPDU的一个拷贝, 所以BID和sender BID都是S1,只是去掉了proposal的flag,增加了agreement的flag,这可以让接收到agreement的端口知道具体是那个端口发出的proposal),具体报文如下图:
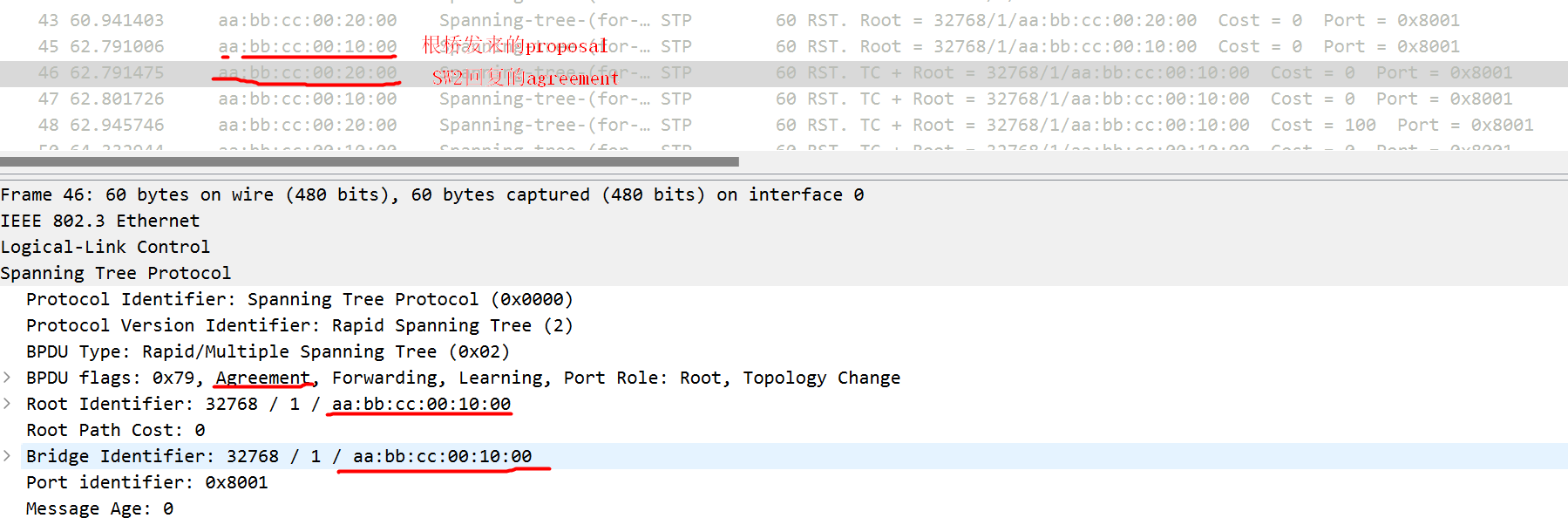
- S1收到agreement置位的BPDU后,将eth0由block置为forwarding,如果没有收到,则会通过discarding、learning切换到forwarding状态(比如下游设备运行STP时就会出现这种场景)
- 以上为一个同步的完成流程,之后S2与S3,S2与S4之间会进行同样的同步协商动作。即S2向S3,S4发送proposal报文,S3,S4选出RP,block非边缘DP,并向下游发送proposal报文(改实例中没有),S3,S4向S2发送agreement报文,并将自身RP置位forwarding,S2将收到agreement报文的DP置位forwarding状态
- 端口状态变成forwarding,之后发送的BPDU就不会有proposal置位了。
- PA同步机制其实就是传递一组PA报文(A是P的拷贝), 由于没有定时器机制,以上流程发生非常快,亚秒级就可完成端口状态的切换。
- 如果发出P=1的报文没有收到A=1的回复,则使用STP一样的机制进行状态转换。比如DP-AP之间,边缘端口但是没有配置portfast的时候。
拓扑变化机制(重要区别)
RSTP的拓扑变化机制与STP有很大的区别,触发机制和传播TC信息都有区别。
STP中链路故障会触发TC(topology change,up or down),RSTP中不会讲链路故障视作TC。RSTP中只有非边缘DP端口状态转换成forwarding时才会视作TC。当RSTP检测到TC时:
- 开启2倍hello time作为TC持续时间。在非边缘DP和RP上生效。
- flush该端口上学到的MAC地址表
- 在TC持续时间内,BPDU中TC置位,从非边缘DP和RP向外发送。
当了邻居收到TC报文后:
- flush除收到TC报文之外的所有端口上的MAC地址表
- 开启TC持续时间计时器,在非边缘DP和RP上生效,并发送TC置位BPDU。
区别于STP中只向RP发送TCN,等待根桥发送TC/TCA置位BPDU,然后等待forward_delay的时间让MAC地址表超时,RSTP可以很快让全网知道TC并flush mac地址表,这样做有利有弊,可能会增加潜在的flooding流量,但同时也快速的清理了潜在的无效MAC地址表信息。
兼容性问题
RSTP向下兼容STP,但是快速收敛的特性就没有了。STP不会处理RSTP的报文。
简单总结
STP中虽然通过portfast、uplinkfast、backbonefast的机制一定程度上加快了STP在特定场景下的收敛,但这些特性时私有了,个厂家实现有差异,而RSTP中将其集成到了标准之中。而P/A协商机制,TC拓扑变化机制的引入更是将拓扑收敛时间降到了一秒内,相对于STP是巨大的提升。但是RSTP也带来了一些问题:
- 必stp配置复杂
- 消耗更多的CPU资源
- 使用根桥cache信息,可能会导致count-in-infinity的问题
RSTP比STP收敛更快的原因是:
- PA机制
- TC机制
- 邻居keepalive机制(3个hello time)
- 集成backbonefast,配置边缘端口(uplinkfast实际是PA机制)
两个实验
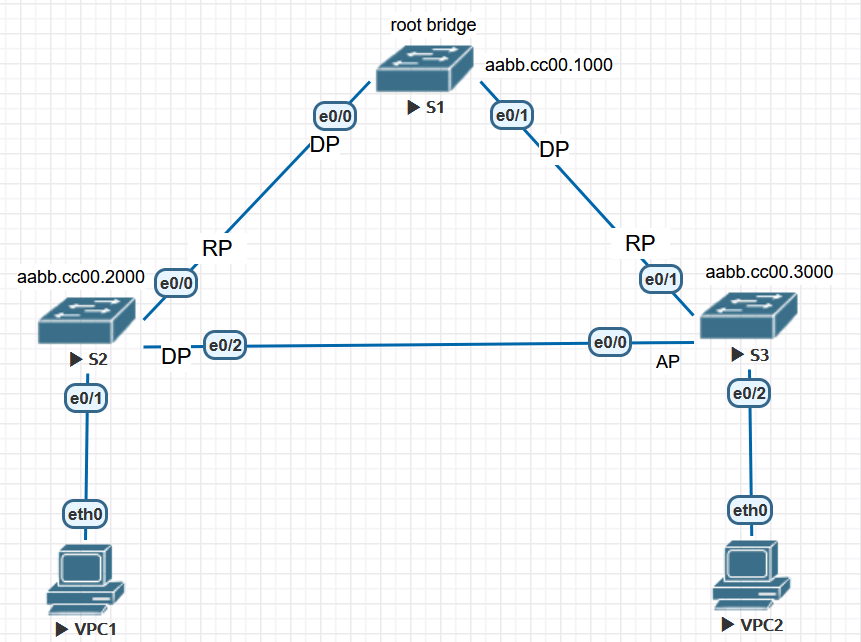
实验拓扑如上,操作步骤如下:
- vpc1和vpc2在同一网段,vpc1持续ping vpc2
- 模拟TC,观察ping中断时间以及端口角色、状态变化
注意实验之前需要正确配置边缘端口,cisco上和配置stp中portfast特性命令一致:
1 | Switch(config-if)#spanning-tree portfast edge // 将接口配置成边缘端口 |
如果没有配置,根据P/A协商机制,当S2的eth0 down掉后,eth1会在discarding、learning、forwarding状态间进行时延转换(30秒)。原因是从eth1发出的proposal报文没有收到agreement回复。
STP中portfast只是让端口跳过状态切换,并且状态变换不会产生TCN,但是RSTP中边缘端口和PA机制有相互作用,注意!
backbonefast特性测试
在S2上shutdown端口eth0,S2的eth2发送inferior BPDU,模拟backbonefast特性测试。ping结果如下:
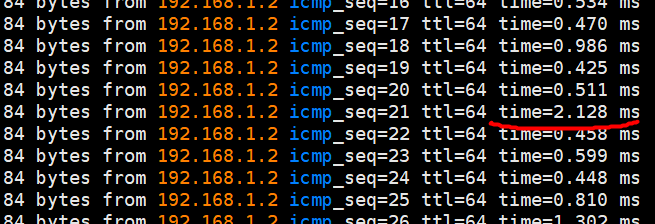
没有发现丢包,只是shutdown瞬间一个包时延大了一些, 相较于STP开启backfast之后依然断流30秒(S3上eth0状态切换时延),提升很巨大。S2上端口状态如下:
1 | Switch#show spanning-tree | begin Interface |
可以看到eth2通过PA协商立即变成RP的forwarding状态,eth1上配置了边缘端口,不参与PA,所以依然是forwarding,eth3上没有配置边缘端口,处于blocking,经过30秒时延转换成forwarding。
S3上eth0端口则在瞬间有AP变成DP forwarding状态,这里不做展示。
uplinkfast特性测试
在S3上shutdown端口eth1,eth0从AP变成RP forwarding状态。ping测试结果保持和上面一致,没有丢包,只是时延增加。S3上端口状态如下:
1 | Switch#show spanning-tree | begin Interface |
对于STP,在vpc1持续ping vpc2刷新mac地址的场景下,在S3上开启uplinkfast特性,shutdown S3的eth1后,大概需要15秒才能恢复通信,eth0从AP直接转换成DP forwarding状态,并发送TCN报文到S2,S2从eth0发送到根桥,收到根桥发来的TC报文后,设置15秒的MAC地址表老化超时,S2上VPC2的MAC地址指向eth0,15秒超时后重新学习,通信恢复。S3收到TCA后停止发送TCN。
参考资料:
Understanding Rapid Spanning Tree Protocol (802.1w)
《802.1w-2001》
《802.1d-2004》